Actor System with Akka Part 2
Recap
In the previous post we demoed a distributed courier recommendation prototype and introduced the actor systems.
In this post we will explain the prototype in some more details.
The Prototype
The most important idea of the prototype is that everything is an actor. Those include the each courier, each restaurant, as well as each grid cell.
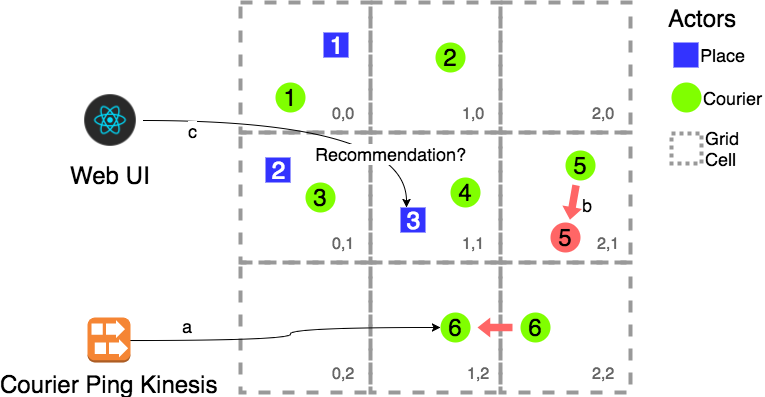
There are three main types of messages passed around in the system:
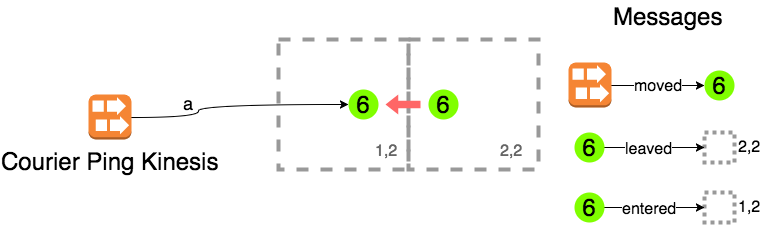
Message Type A: courier moving
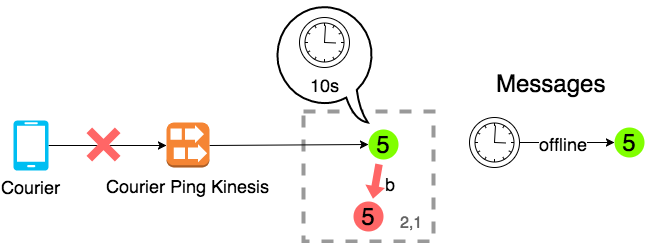
Message Type B: courier going offline
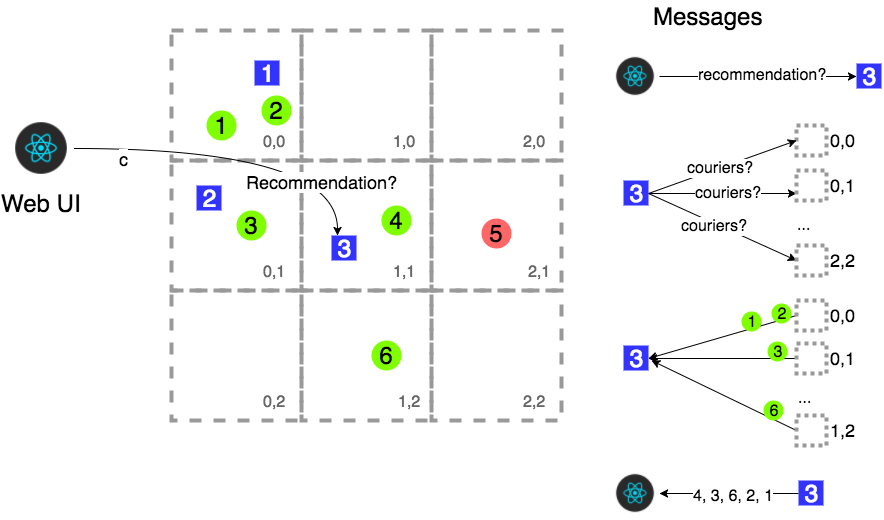
Message Type C: courier recommendation
Going Distributed
The idea of distributing actors across multiple server instances is very similar to how most NoSQL DBs work. The core concept is sharding:
- Each actor is assigned a unique ID
- A hash is computed from the ID
- Each server instance is assigned several shards, each shard maps to a range (aka partition) of the hash space
- Actors are allocated to instances based on their hash and the instance’s partition
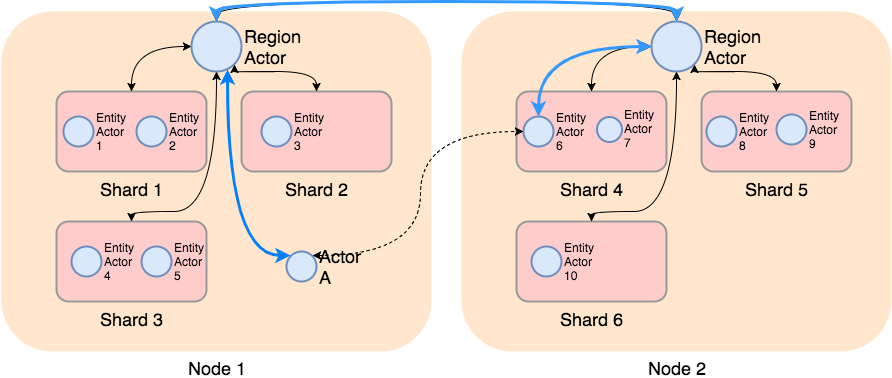
(The blue line illustrates the flow of data)
Note actor A is not sharded, because it has only one instance (a singleton).
Data Persistence and Event Sourcing
The Akka doc provides a very good intro to event sourcing.
The fundamental idea is to model state transition as an ordered sequence of events and actions. Then the events can be stored into a DB and played back later to reconstruct the original state.
This is exactly how Akka persistence works: each actor stores the events (triggered by messages) as they happen, and replay them when it restarts.
There are two types of data that Akka persistence support: events and snapshots. Snapshots are used to make the replay process quicker.
In the prototype we used Cassandra for its performance. Akka also supports other storage backends, all using a common API (so switching backend requires no code change).
Actor Supervision
An actor can fail, just like any running systems.
Akka provides a default supervision strategy for handling actor failure called the error kernel.
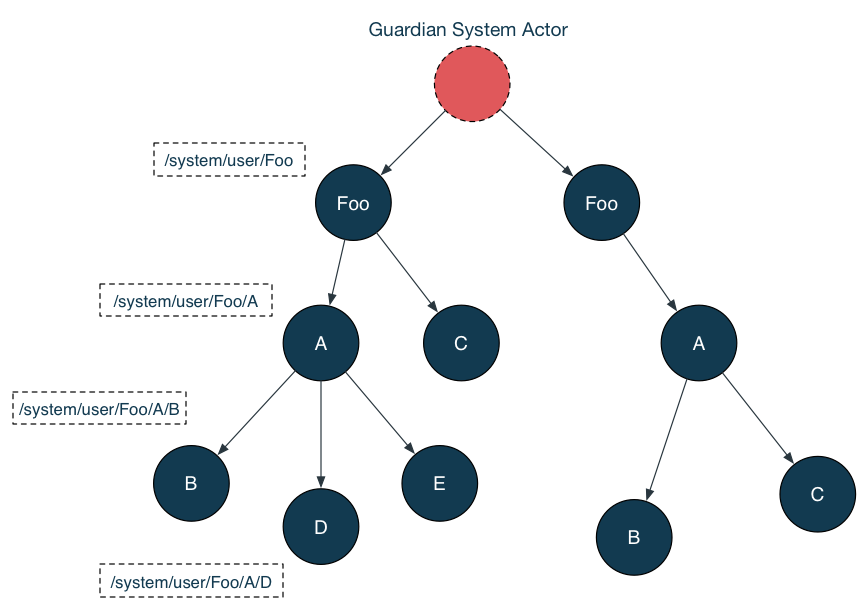 (From Akka doc)
(From Akka doc)
The idea is that all actors form a tree structure, with parent nodes supervising their immediate children. The default strategy is to restart the failed children, but users can define other strategies as well.
In the prototype for example, if a node fails, then all of the shards are migrated to other nodes.
Conclusion
In this post we explored the architecture of the prototype as well as some of the important features of Akka.
In the next post I will explain some of the challenges of distributed systems and how we can solve them.