Actor System with Akka Part 3
Recap
In the previous post explained the architecture of the courier recommendation prototype and features of Akka.
In this post we will explain some of the challenges faced by distributed systems, and how we can solve them.
Has it failed?
Distributed systems need to exchange data between nodes to ensure data consistency (unless you have a microservice with a load balancer, in which case server nodes are unaware of each other).
Due to network jitters and other factors, distributed systems are very prone to communication failures (that’s essentially why the CAP theorem was proposed).
For distributed actors, the challenge is to detect when a node has failed and migrate actors over to other nodes.
There are two important questions to answer:
- When a nodes has failed?
- Which nodes to migrate to?
When has it failed?
Nodes in a Akka cluster sends heartbeat messages to each other periodically. Using a fixed threshold on the time-since-last-heartbeat (TSLH) to mark a node as down is, however, not a good idea.
This is because the network traffic can experience fluctuation over time, and a fixed threshold can produce a lot of false positives.
Akka implements an adaptive threshold called a Phi detector, which takes into account the TSLH of the last (say 100) heartbeats and produces a threshold based on the statistical distribution.
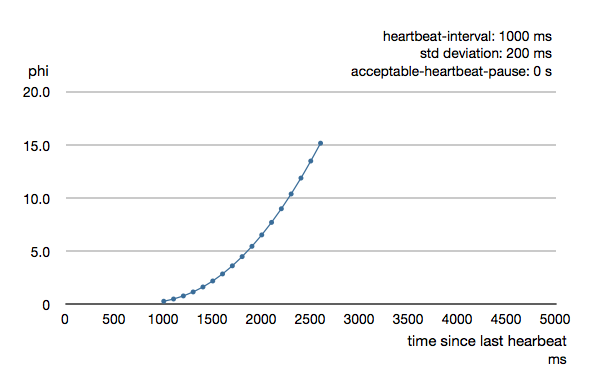 (From Akka doc)
(From Akka doc)
Which nodes to migrate to?
If a network cut happens, then both sides of the cut will see the other side as down. If they both try to migrate actors to their side, the we will end up with two identical clusters (aka a split brain)!
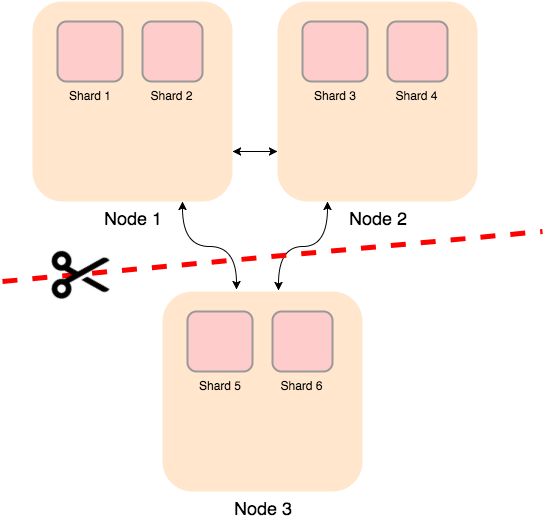 =>
=>
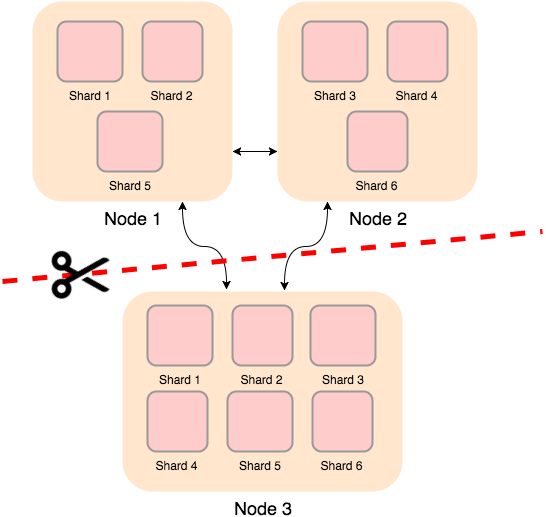
To avoid this happening, Akka implements several strategies:
- Majority wins
- Oldest wins
- Referee wins
Has a message been delivered?
Sometimes you want to ensure no messages are missed. Akka by default uses “at-most-once” delivery semantic.
To enforce an “at-least-once” strategy, we must use data persistence and the playback feature of Akka. The official doc gives an excellent overview of this.
A related problem is how to ensure messages are delivered in order. Generally this is only possible for two directly communicating actors, since transitive actors can easily mess up the ordering. If strict ordering is necessary, then either use a single routing actor, or a queue service (Kafka, Kinesis, etc).
How to upgrade?
This is an area often overlooked by system designers, and later becomes the Achilles heel.
The main issue is that the system often needs to be online (e.g., a monitoring system) while upgrading, and a rolling update is usually required in this case.
To ensure the old and the new codebase can work together, it is important to maintain the compatibility of messages (since actors communicate only with messages). Hence message versioning is a necessary feature, and serialization technologies must be chosen carefully.
For the prototype, we used Protobuf to generate the Scala code for the messages. We did not use the default Java serialization because it is both inefficient and not tolerant to changes.
UDP (implemented by Akka’s artery project) is also used instead of TCP for inter-node communication, because TCP carries a large overhead and the error checking is handled more efficiently by Akka (Aeron to be more precise) directly.
Other Considerations
- Monitoring is supported by several libraries. The Kamon project provides a free and decent library to collect and report system metrics. Another more powerful tool is Lightbend Telemetry, which provides more detailed metrics but requires more to setup.
- The codebase can/should be split into multiple projects to avoid a big monolith. Akka provides a feature to split the nodes by roles.
- Akka can be used in conjunction with other systems to build a full stack of active/reactive applications. Examples are data ETL pipelines, message distribution systems and monitoring systems.
Conclusion
In this series of blogs we examined the power of actor systems using a prototype. The model provides a good solution to both distributed and reactive programming problems.
I hope you have enjoyed the series, and have gained a basic understanding of the actor model to design and build more complex distributed systems.